Често добавянето на правилната метаинформация към PDF файловете може да бъде досадно. Аз самият сортирам изтеглените PDF файлове от абонаментния си акаунт в Heise IX в личната си библиотека в Calibre.
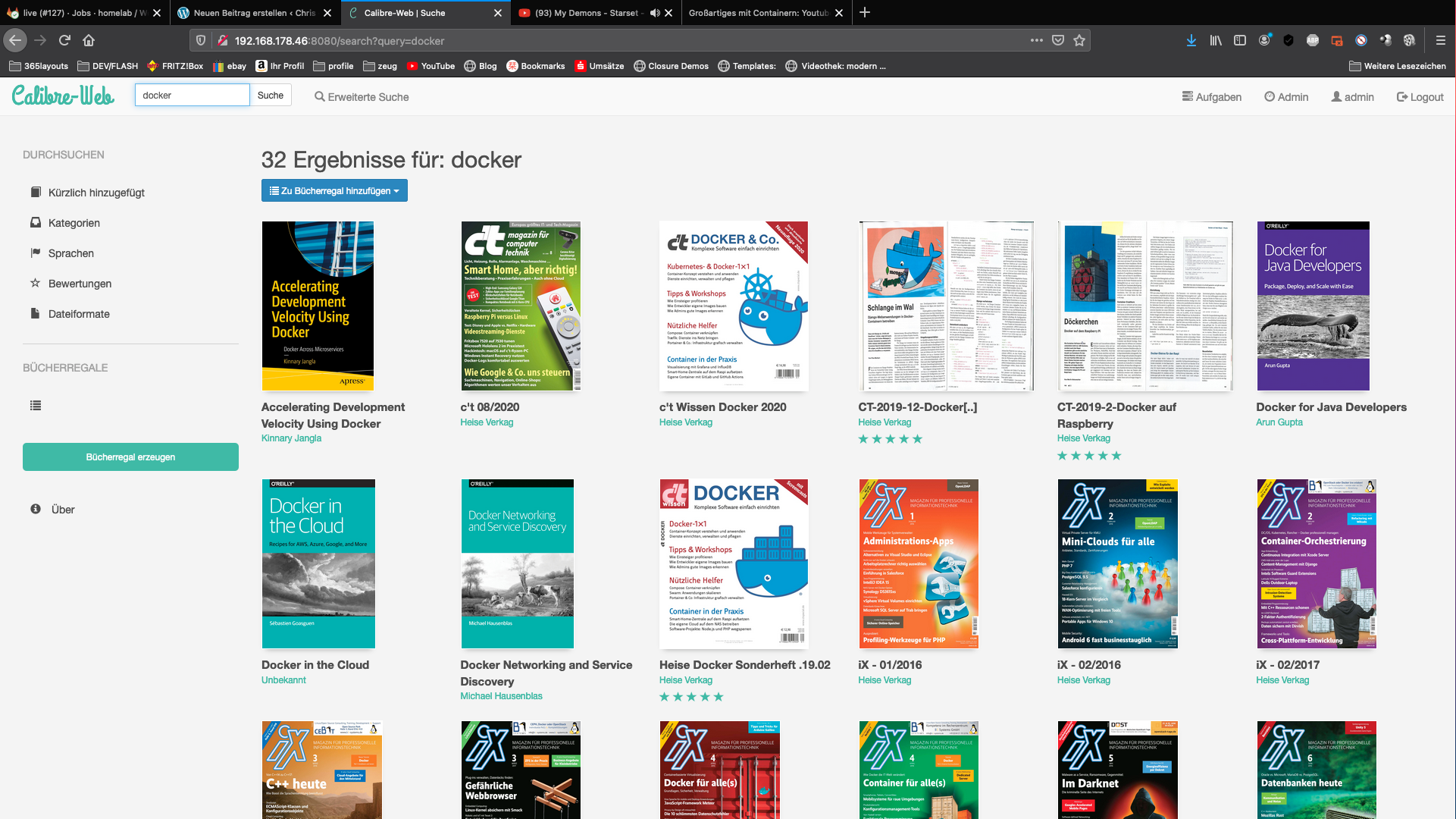
Тъй като този процес се повтаря всеки месец, измислих следната конфигурация. Влача само новите PDF файлове в библиотеката си.
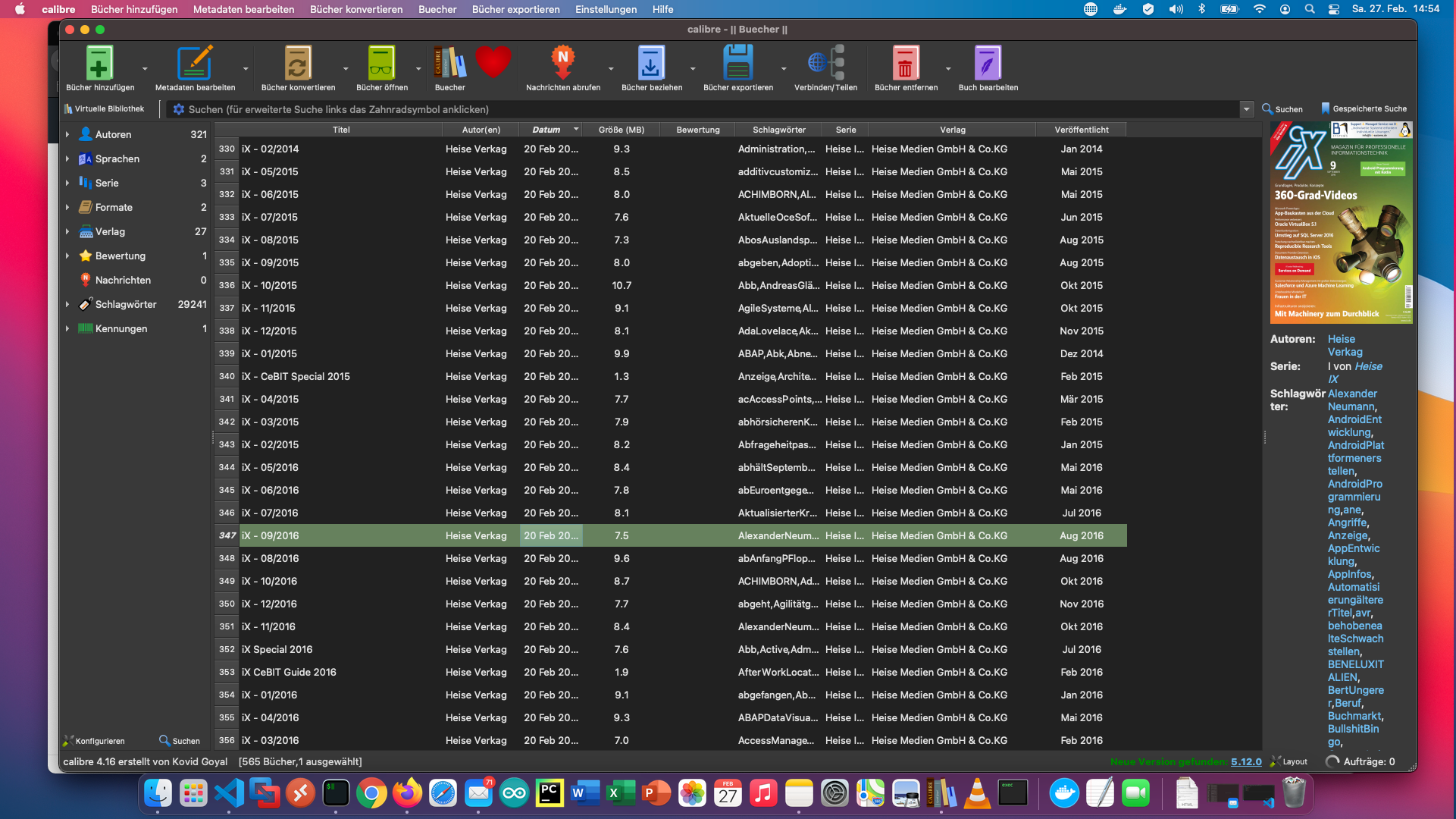
Създадох контейнер, който получава библиотеката ми в Calibre като том (-v …:/books). В този контейнер съм инсталирал следните пакети:
$ apt-get update && apt-get install -y xpdf calibre
#!/bin/bash
export LANG=C.UTF-8
mkdir /tmp/worker1/
find /books/ -type f -iname '*.pdf' -newermt 20201201 -print0 |
while IFS= read -r -d '' line; do
calibreID=$(echo "$line" | sed -r 's/.*\(([0-9]+)\).*/\1/g')
echo "bearbeite $clearName"
echo "id $calibreID";
cp "$line" /tmp/worker1/test.pdf
echo "ocr "
pdftotext -f 0 -l 5 /tmp/worker1/test.pdf /tmp/worker1/tmp.txt
echo "text aufbereitung"
cat /tmp/worker1/tmp.txt | grep -i -F -w -v -f /books/blacklist.txt | sed -r s/[^a-zA-ZäöüÄÖÜ]+//g | grep -iE '[A-Za-z]{2,212}' | sed ':begin;$!N;s/\n/,/;tbegin' > /tmp/worker1/final.txt
calibredb set_metadata --with-library /books/ --field cover:"cover.jpg" --field tags:"$(cat /tmp/worker1/final.txt) " --field series:"Heise IX" --field languages:"Deutsch" --field authors:"Heise Verkag" $calibreID
rm /tmp/worker1/*
done
С командата “calibredb set_metadata” задавам всичко останало като тагове. Резултатът изглежда така:
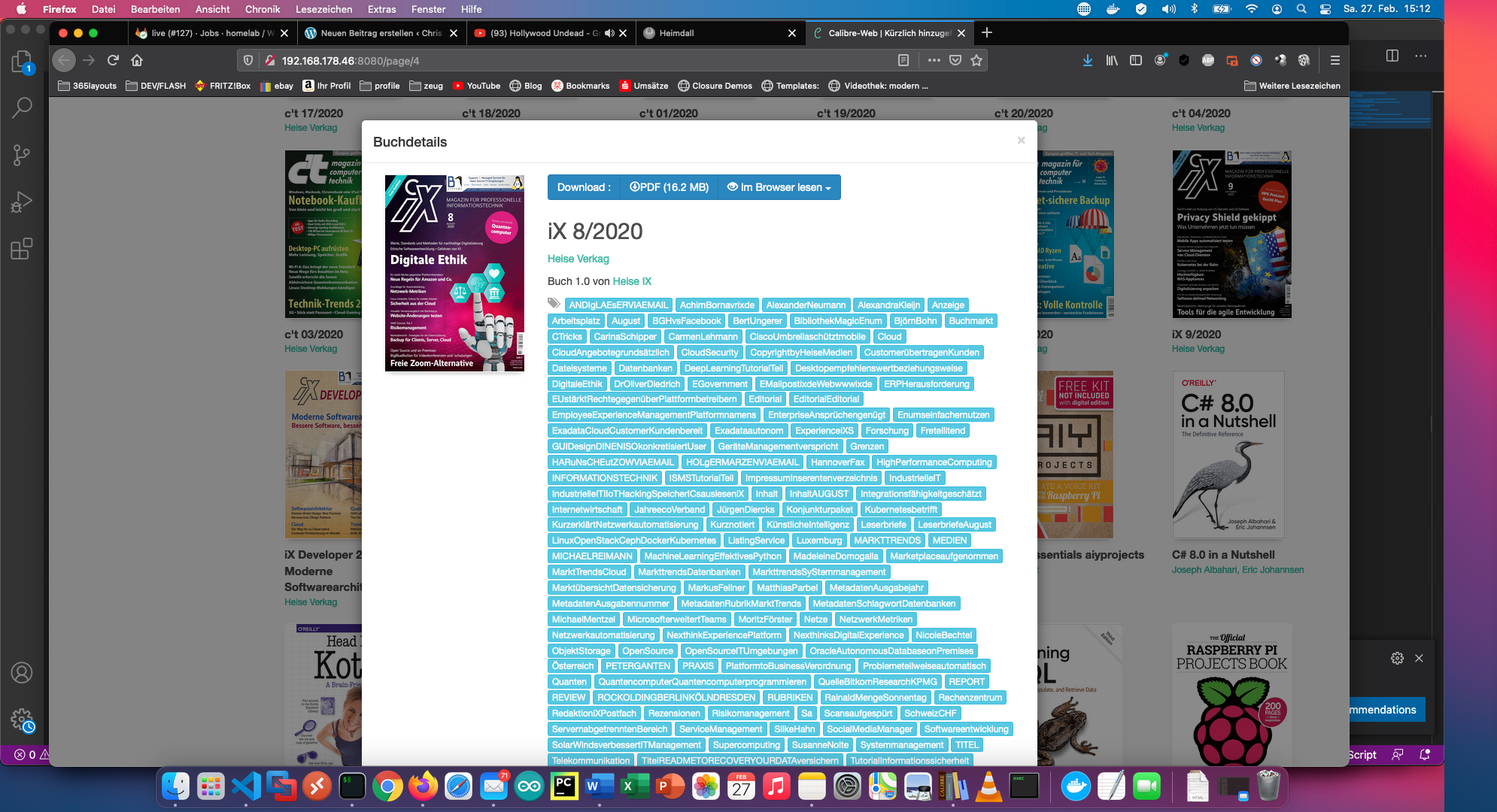
Скриптът е достъпен и в Github: https://github.com/ChristianKnedel/heise-ix-reader-for-calibre .