Het kan vaak lastig zijn om de juiste meta-info aan PDF’s toe te voegen. Zelf sorteer ik de gedownloade PDF’s van mijn Heise IX abonnementsaccount in mijn privé Calibre bibliotheek.
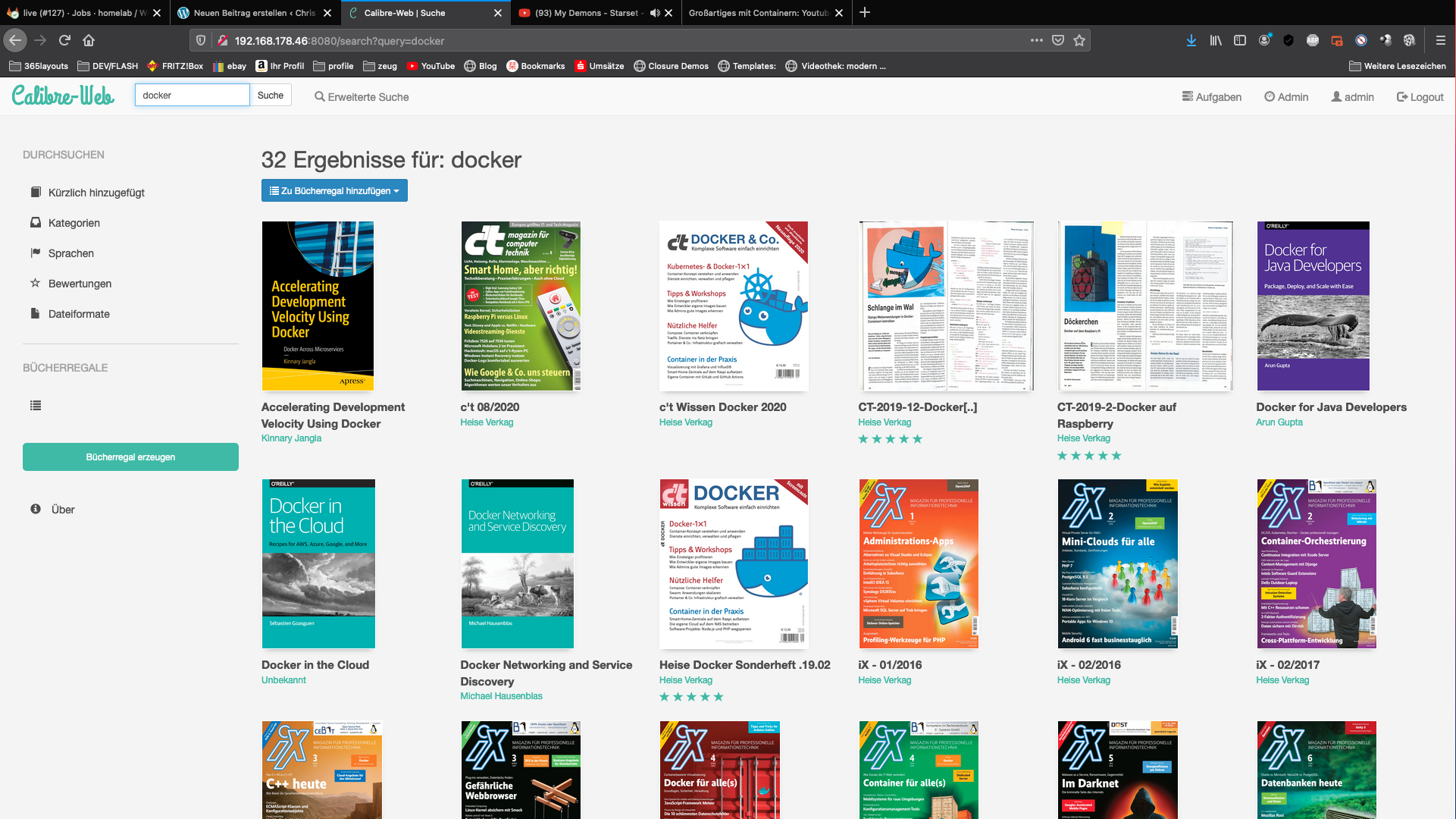
Omdat dit proces zich elke maand herhaalt, heb ik de volgende opzet bedacht. Ik sleep alleen mijn nieuwe PDF’s naar mijn bibliotheek.
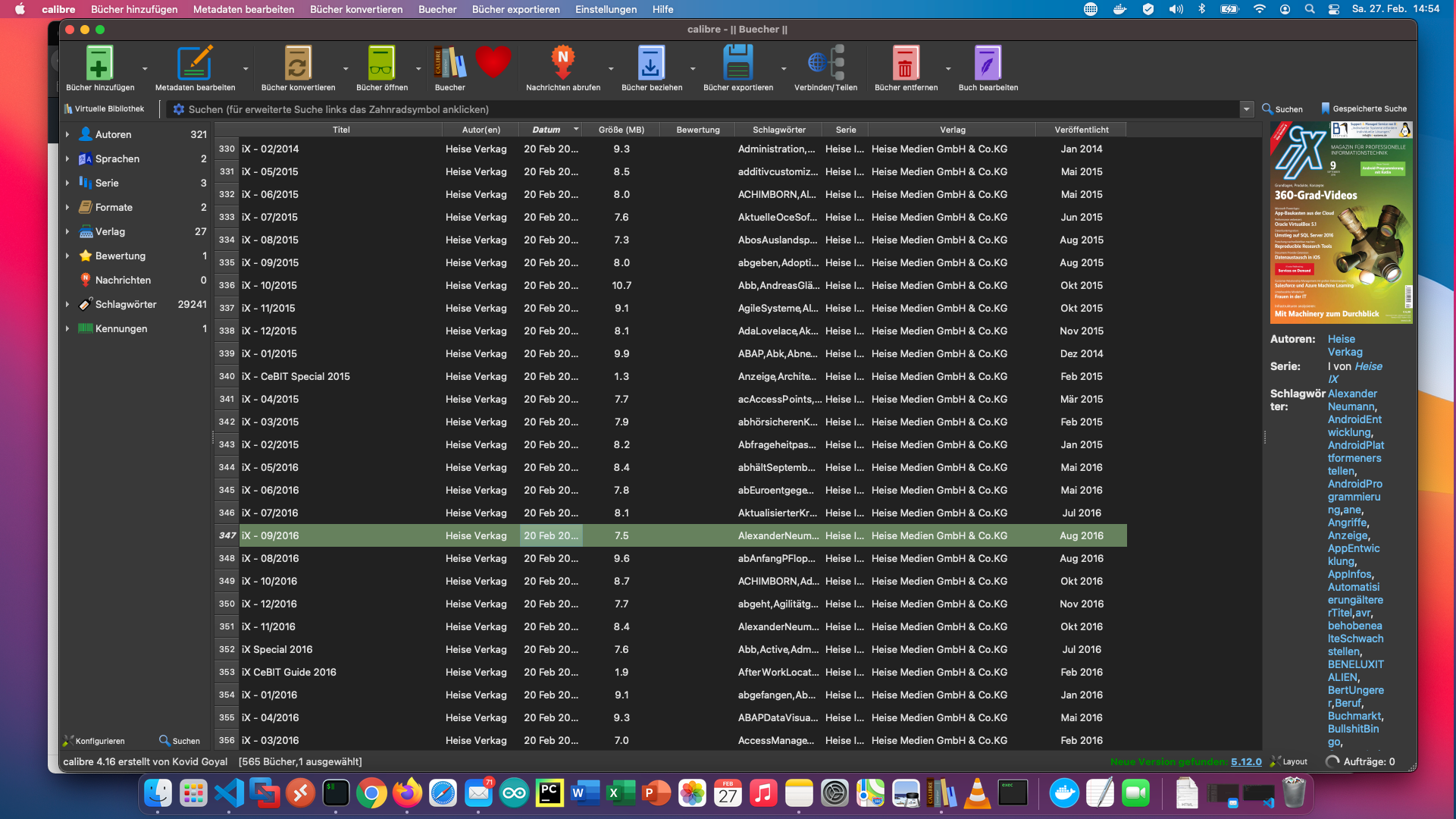
Ik heb een container gemaakt die mijn Calibre bibliotheek als een volume krijgt (-v …:/books). In deze container heb ik de volgende pakketten geïnstalleerd:
$ apt-get update && apt-get install -y xpdf calibre
#!/bin/bash
export LANG=C.UTF-8
mkdir /tmp/worker1/
find /books/ -type f -iname '*.pdf' -newermt 20201201 -print0 |
while IFS= read -r -d '' line; do
calibreID=$(echo "$line" | sed -r 's/.*\(([0-9]+)\).*/\1/g')
echo "bearbeite $clearName"
echo "id $calibreID";
cp "$line" /tmp/worker1/test.pdf
echo "ocr "
pdftotext -f 0 -l 5 /tmp/worker1/test.pdf /tmp/worker1/tmp.txt
echo "text aufbereitung"
cat /tmp/worker1/tmp.txt | grep -i -F -w -v -f /books/blacklist.txt | sed -r s/[^a-zA-ZäöüÄÖÜ]+//g | grep -iE '[A-Za-z]{2,212}' | sed ':begin;$!N;s/\n/,/;tbegin' > /tmp/worker1/final.txt
calibredb set_metadata --with-library /books/ --field cover:"cover.jpg" --field tags:"$(cat /tmp/worker1/final.txt) " --field series:"Heise IX" --field languages:"Deutsch" --field authors:"Heise Verkag" $calibreID
rm /tmp/worker1/*
done
Met het commando “calibredb set_metadata” stel ik alles in als tags. Het resultaat ziet er zo uit:
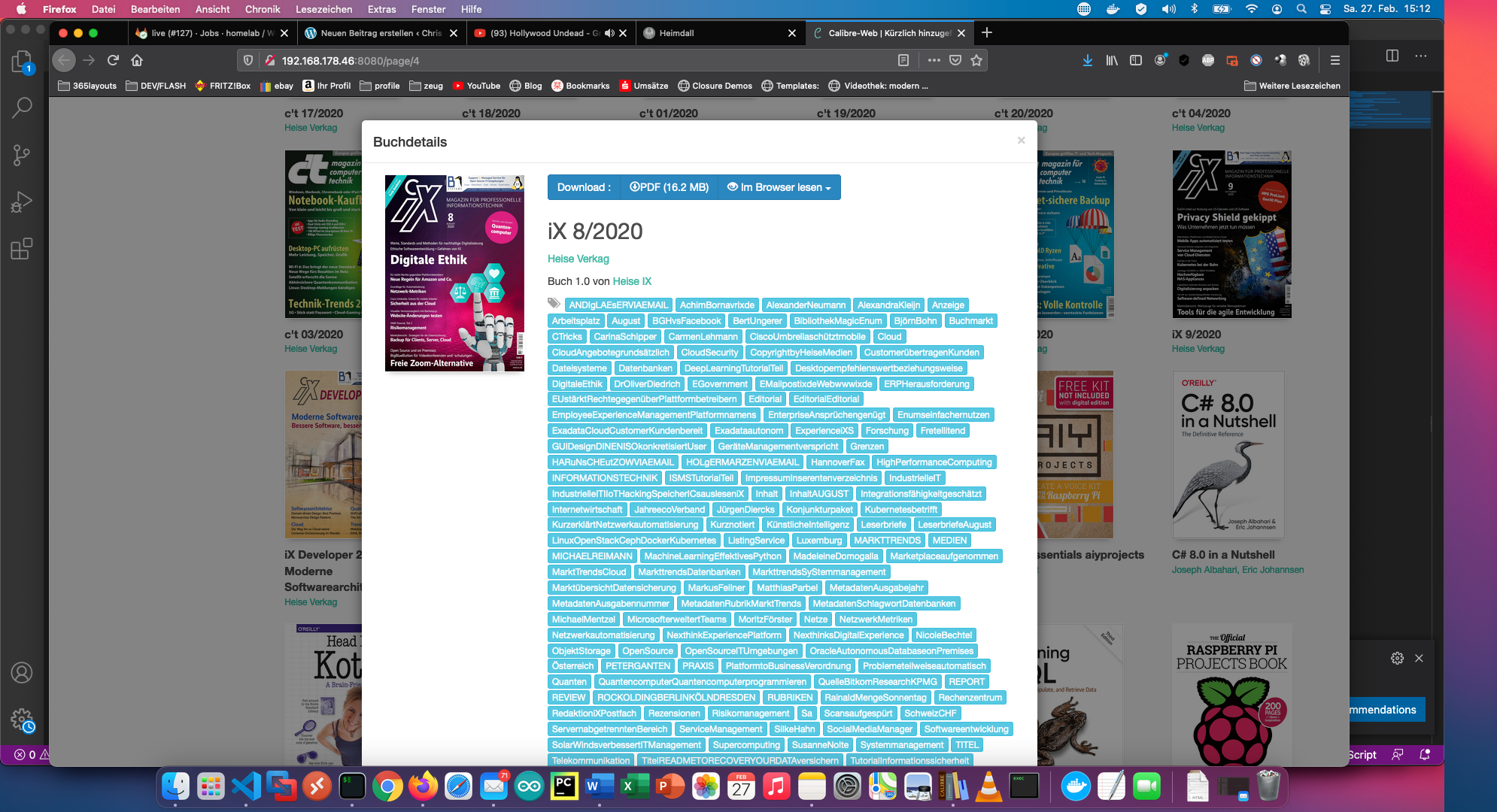
Het script is ook beschikbaar op Github: https://github.com/ChristianKnedel/heise-ix-reader-for-calibre .