Dodawanie właściwych metainformacji do plików PDF może być często żmudne. Ja sam sortuję pobrane pliki PDF z mojego konta subskrypcji Heise IX do mojej prywatnej biblioteki Calibre.
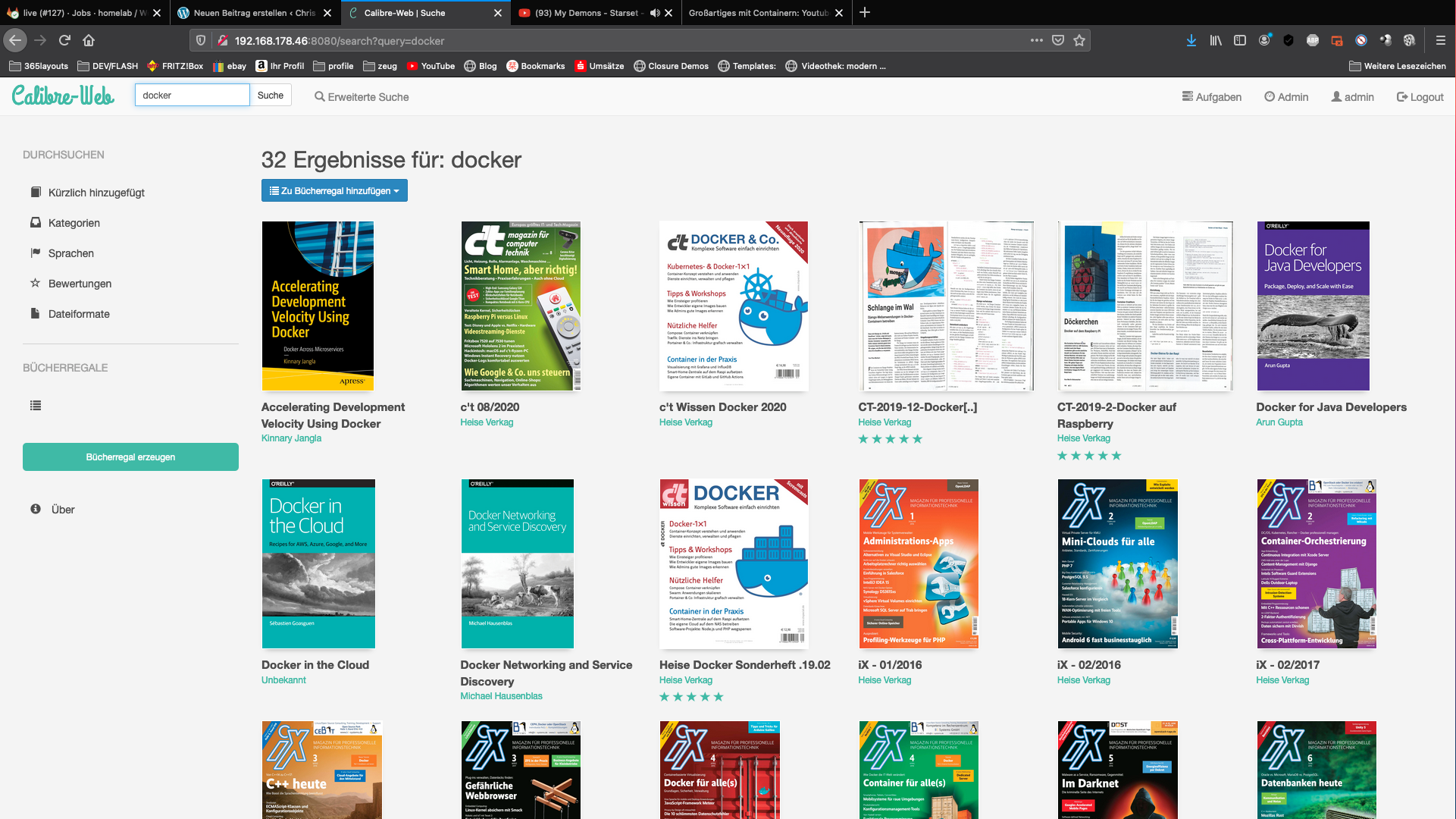
Ponieważ proces ten powtarza się co miesiąc, wymyśliłem następującą konfigurację. Do biblioteki przeciągam tylko nowe pliki PDF.
Utworzyłem kontener, który pobiera moją bibliotekę Calibre jako wolumin (-v …:/books). W tym kontenerze zainstalowałem następujące pakiety:
$ apt-get update && apt-get install -y xpdf calibre
#!/bin/bash
export LANG=C.UTF-8
mkdir /tmp/worker1/
find /books/ -type f -iname '*.pdf' -newermt 20201201 -print0 |
while IFS= read -r -d '' line; do
calibreID=$(echo "$line" | sed -r 's/.*\(([0-9]+)\).*/\1/g')
echo "bearbeite $clearName"
echo "id $calibreID";
cp "$line" /tmp/worker1/test.pdf
echo "ocr "
pdftotext -f 0 -l 5 /tmp/worker1/test.pdf /tmp/worker1/tmp.txt
echo "text aufbereitung"
cat /tmp/worker1/tmp.txt | grep -i -F -w -v -f /books/blacklist.txt | sed -r s/[^a-zA-ZäöüÄÖÜ]+//g | grep -iE '[A-Za-z]{2,212}' | sed ':begin;$!N;s/\n/,/;tbegin' > /tmp/worker1/final.txt
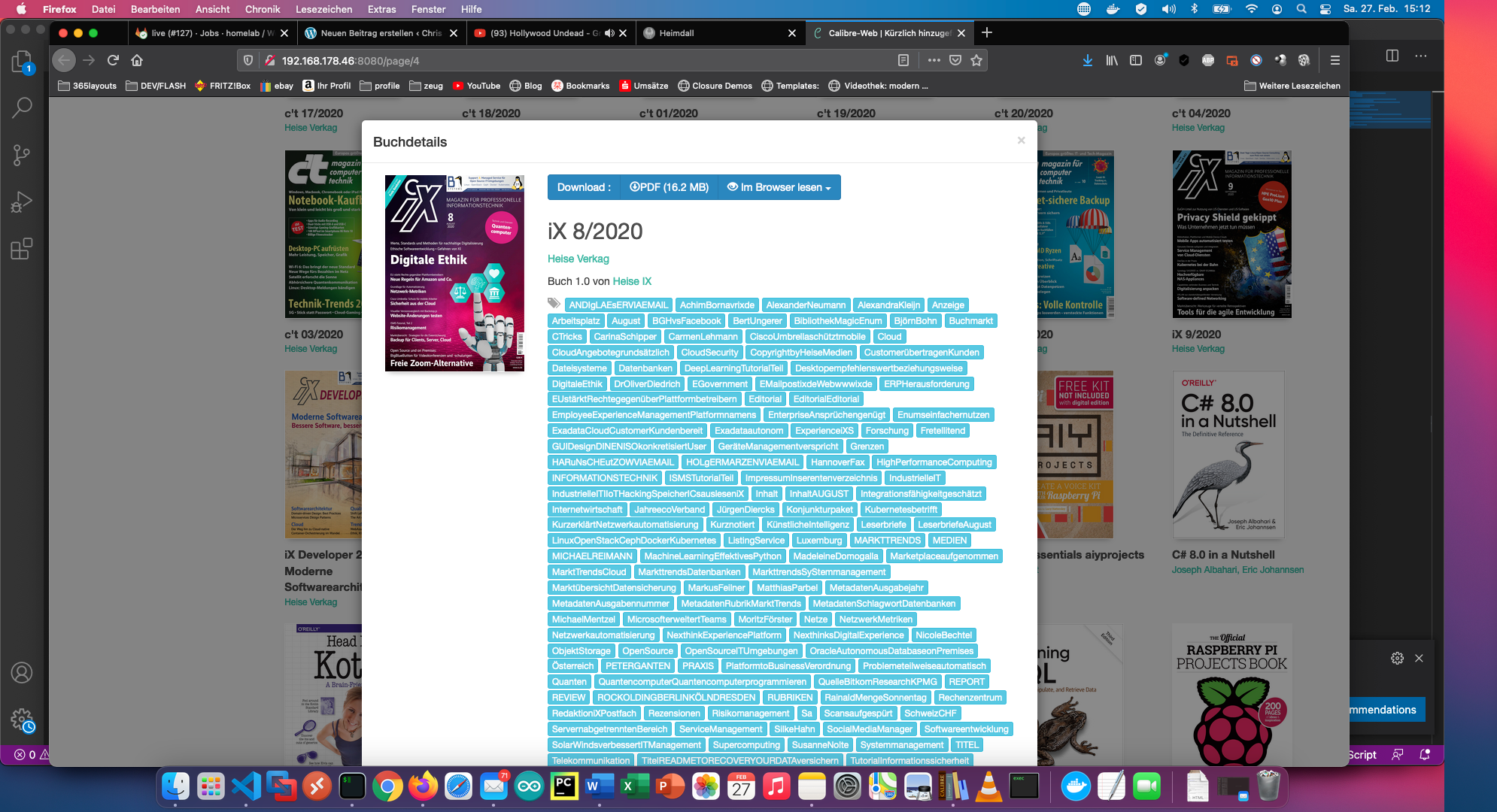
calibredb set_metadata --with-library /books/ --field cover:"cover.jpg" --field tags:"$(cat /tmp/worker1/final.txt) " --field series:"Heise IX" --field languages:"Deutsch" --field authors:"Heise Verkag" $calibreID
rm /tmp/worker1/*
done
Za pomocą polecenia “calibredb set_metadata” ustawiam wszystko inne jako tagi. Wynik wygląda następująco:
Skrypt jest również dostępny w serwisie Github: https://github.com/ChristianKnedel/heise-ix-reader-for-calibre .