Adesea, adăugarea de meta-informații corecte la PDF-uri poate fi plictisitoare. Eu însumi sortez PDF-urile descărcate din contul meu de abonament Heise IX în biblioteca mea privată Calibre.
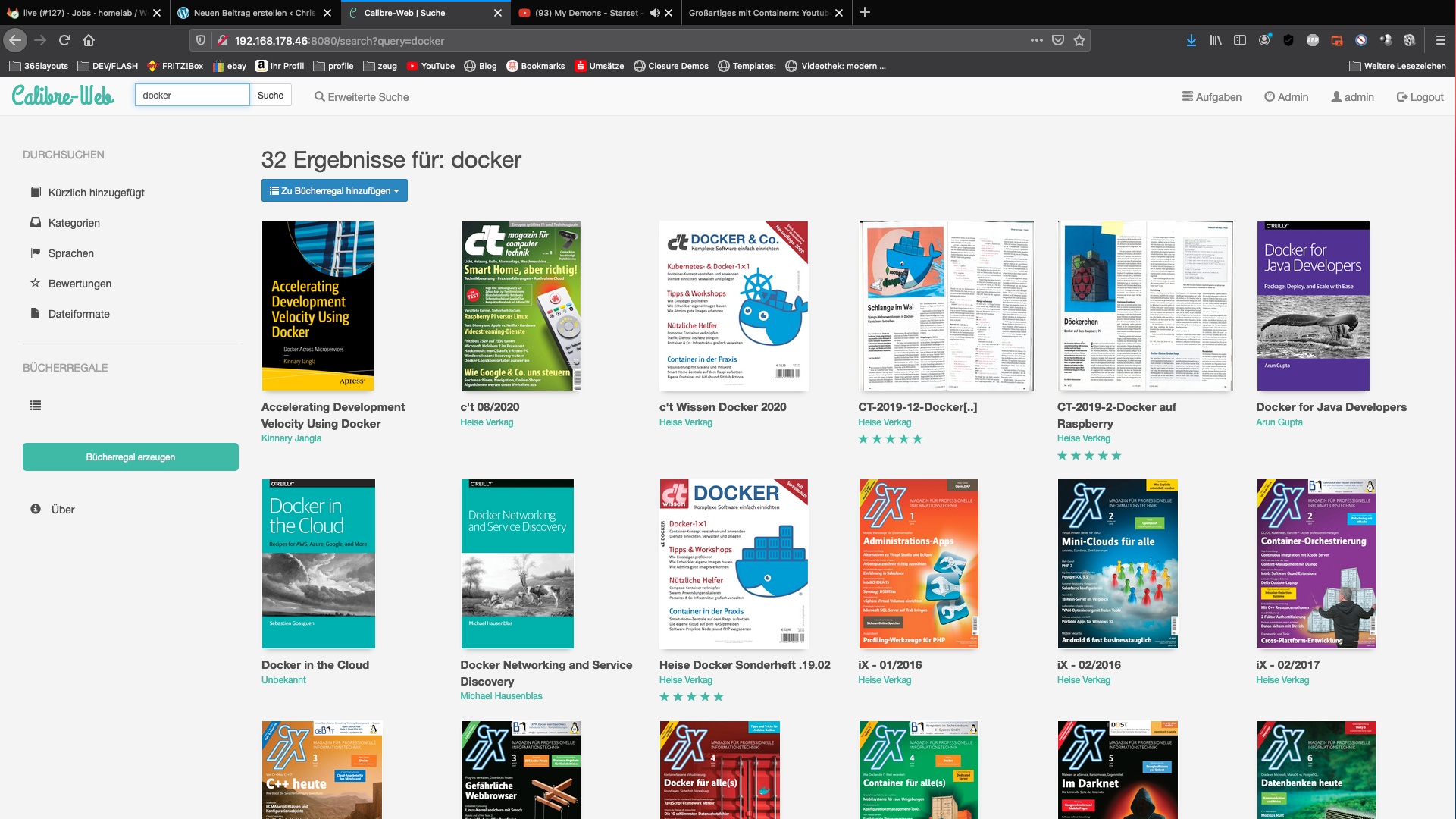
Deoarece acest proces se repetă în fiecare lună, am ajuns la următoarea configurație. Trag doar noile PDF-uri în biblioteca mea.
Am creat un container care primește biblioteca mea Calibre ca volum (-v …:/books). În acest container am instalat următoarele pachete:
$ apt-get update && apt-get install -y xpdf calibre
#!/bin/bash
export LANG=C.UTF-8
mkdir /tmp/worker1/
find /books/ -type f -iname '*.pdf' -newermt 20201201 -print0 |
while IFS= read -r -d '' line; do
calibreID=$(echo "$line" | sed -r 's/.*\(([0-9]+)\).*/\1/g')
echo "bearbeite $clearName"
echo "id $calibreID";
cp "$line" /tmp/worker1/test.pdf
echo "ocr "
pdftotext -f 0 -l 5 /tmp/worker1/test.pdf /tmp/worker1/tmp.txt
echo "text aufbereitung"
cat /tmp/worker1/tmp.txt | grep -i -F -w -v -f /books/blacklist.txt | sed -r s/[^a-zA-ZäöüÄÖÜ]+//g | grep -iE '[A-Za-z]{2,212}' | sed ':begin;$!N;s/\n/,/;tbegin' > /tmp/worker1/final.txt
calibredb set_metadata --with-library /books/ --field cover:"cover.jpg" --field tags:"$(cat /tmp/worker1/final.txt) " --field series:"Heise IX" --field languages:"Deutsch" --field authors:"Heise Verkag" $calibreID
rm /tmp/worker1/*
done
Cu comanda “calibredb set_metadata” am setat toate celelalte ca etichete. Rezultatul arată în felul următor:
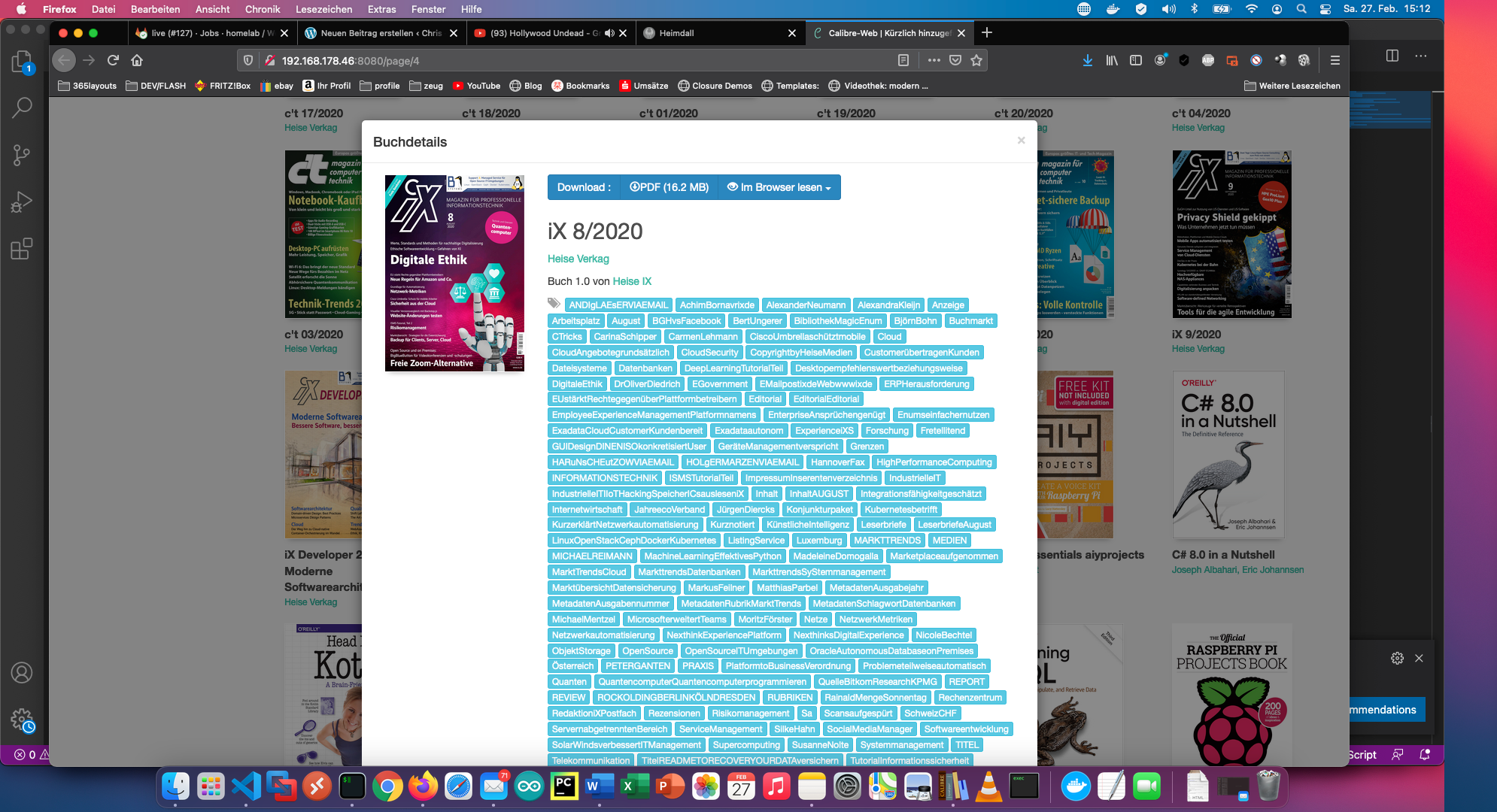
Scriptul este de asemenea disponibil pe Github: https://github.com/ChristianKnedel/heise-ix-reader-for-calibre .