Pridávanie správnych metainformácií do súborov PDF môže byť často zdĺhavé. Ja sám triedim stiahnuté PDF súbory z môjho predplatiteľského účtu Heise IX do mojej súkromnej knižnice Calibre.
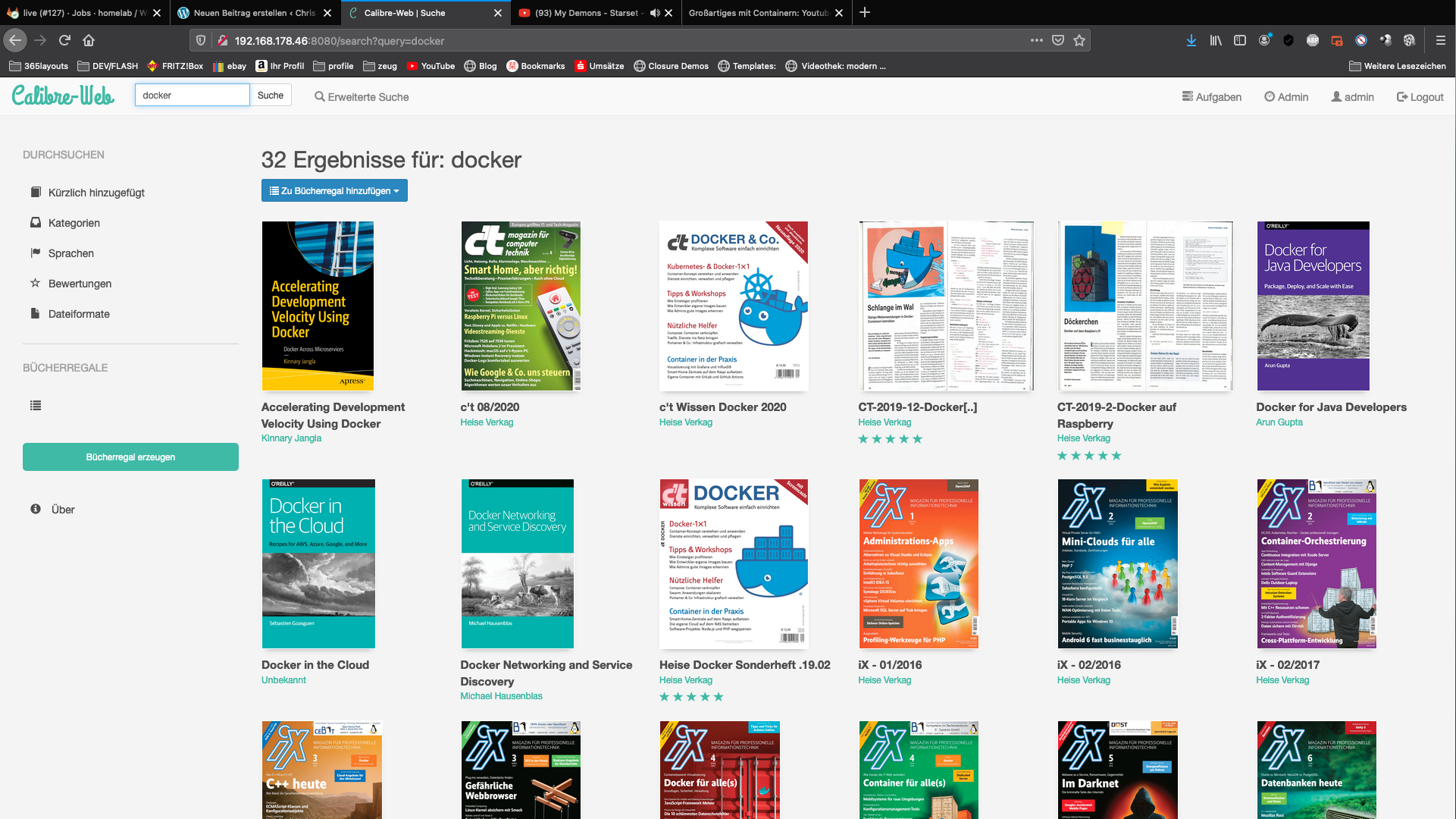
Keďže sa tento proces opakuje každý mesiac, vymyslel som nasledujúce nastavenie. Do svojej knižnice preťahujem len nové súbory PDF.
Vytvoril som kontajner, ktorý získava moju knižnicu Calibre ako zväzok (-v …:/books). Do tohto kontajnera som nainštaloval nasledujúce balíky:
$ apt-get update && apt-get install -y xpdf calibre
#!/bin/bash
export LANG=C.UTF-8
mkdir /tmp/worker1/
find /books/ -type f -iname '*.pdf' -newermt 20201201 -print0 |
while IFS= read -r -d '' line; do
calibreID=$(echo "$line" | sed -r 's/.*\(([0-9]+)\).*/\1/g')
echo "bearbeite $clearName"
echo "id $calibreID";
cp "$line" /tmp/worker1/test.pdf
echo "ocr "
pdftotext -f 0 -l 5 /tmp/worker1/test.pdf /tmp/worker1/tmp.txt
echo "text aufbereitung"
cat /tmp/worker1/tmp.txt | grep -i -F -w -v -f /books/blacklist.txt | sed -r s/[^a-zA-ZäöüÄÖÜ]+//g | grep -iE '[A-Za-z]{2,212}' | sed ':begin;$!N;s/\n/,/;tbegin' > /tmp/worker1/final.txt
calibredb set_metadata --with-library /books/ --field cover:"cover.jpg" --field tags:"$(cat /tmp/worker1/final.txt) " --field series:"Heise IX" --field languages:"Deutsch" --field authors:"Heise Verkag" $calibreID
rm /tmp/worker1/*
done
Príkazom “calibredb set_metadata” nastavím všetko ostatné ako značky. Výsledok vyzerá takto:
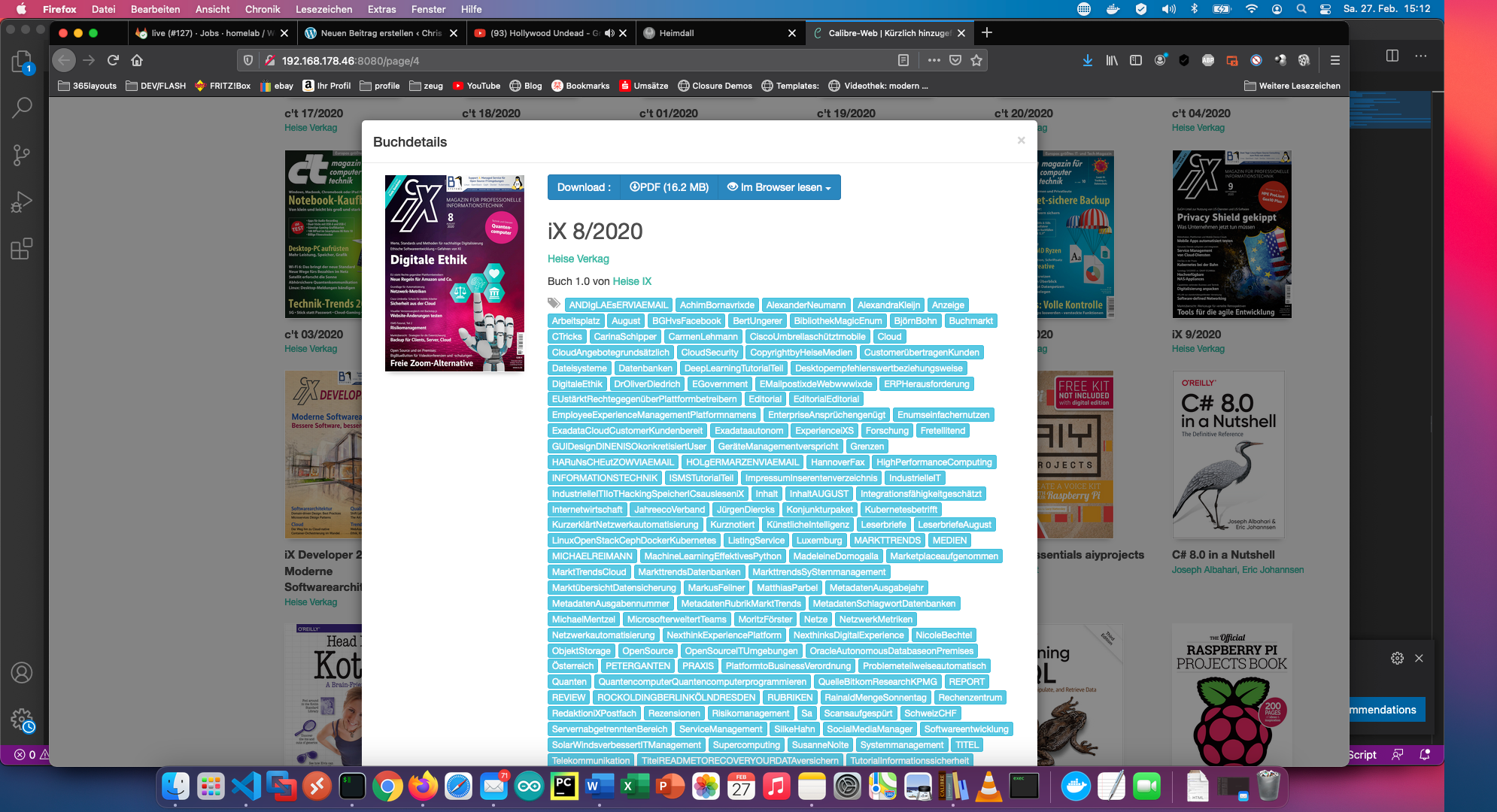
Skript je k dispozícii aj na Githube: https://github.com/ChristianKnedel/heise-ix-reader-for-calibre .