Det kan ofta vara besvärligt att lägga till rätt metainformation i PDF-filer. Jag sorterar själv de nedladdade PDF:erna från mitt Heise IX-abonnemangskonto i mitt privata Calibre-bibliotek.
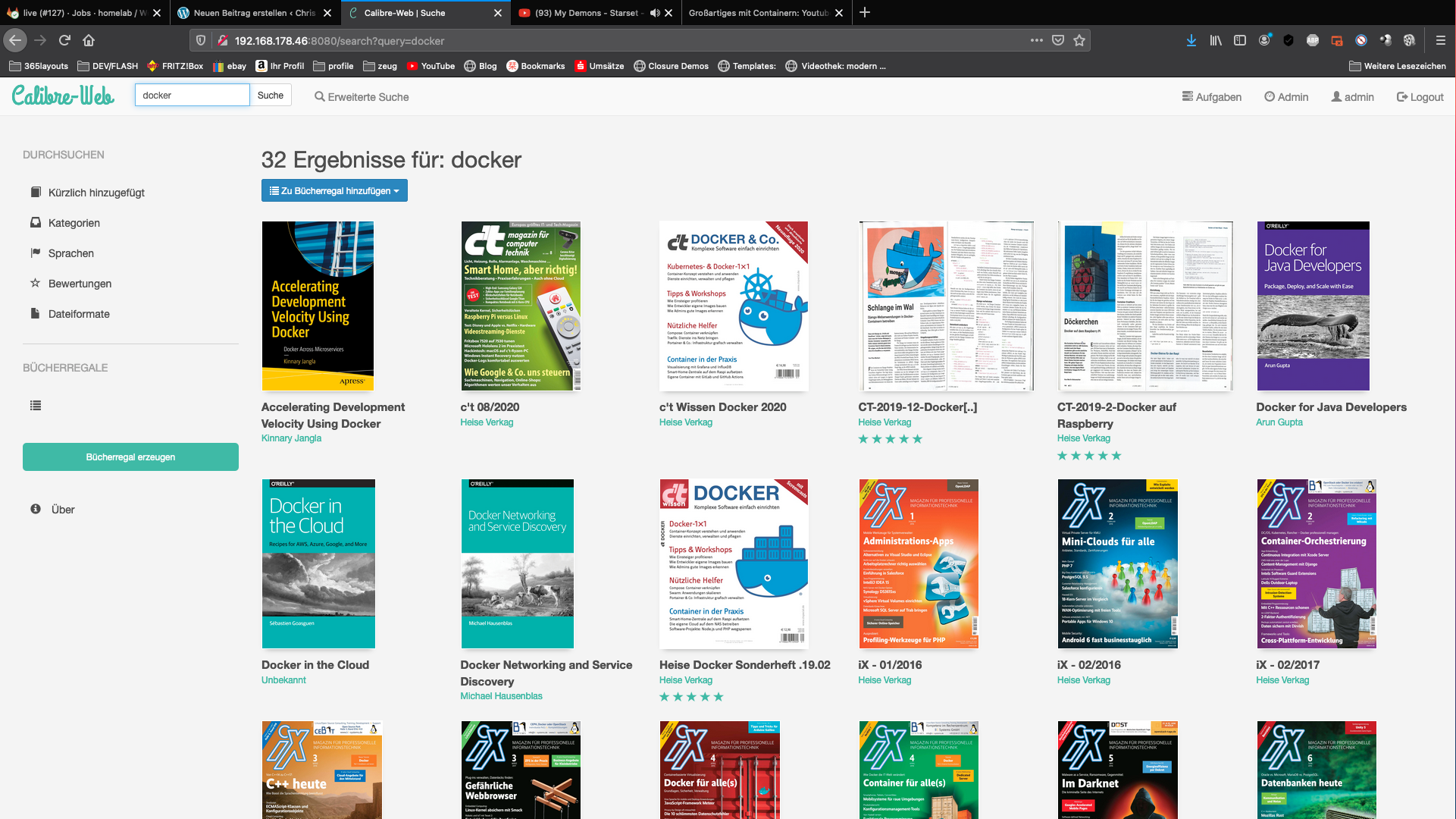
Eftersom denna process upprepas varje månad har jag kommit fram till följande upplägg. Jag drar bara mina nya PDF-filer till mitt bibliotek.
Jag har skapat en behållare som hämtar mitt Calibre-bibliotek som en volym (-v …:/books). I denna behållare har jag installerat följande paket:
$ apt-get update && apt-get install -y xpdf calibre
#!/bin/bash
export LANG=C.UTF-8
mkdir /tmp/worker1/
find /books/ -type f -iname '*.pdf' -newermt 20201201 -print0 |
while IFS= read -r -d '' line; do
calibreID=$(echo "$line" | sed -r 's/.*\(([0-9]+)\).*/\1/g')
echo "bearbeite $clearName"
echo "id $calibreID";
cp "$line" /tmp/worker1/test.pdf
echo "ocr "
pdftotext -f 0 -l 5 /tmp/worker1/test.pdf /tmp/worker1/tmp.txt
echo "text aufbereitung"
cat /tmp/worker1/tmp.txt | grep -i -F -w -v -f /books/blacklist.txt | sed -r s/[^a-zA-ZäöüÄÖÜ]+//g | grep -iE '[A-Za-z]{2,212}' | sed ':begin;$!N;s/\n/,/;tbegin' > /tmp/worker1/final.txt
calibredb set_metadata --with-library /books/ --field cover:"cover.jpg" --field tags:"$(cat /tmp/worker1/final.txt) " --field series:"Heise IX" --field languages:"Deutsch" --field authors:"Heise Verkag" $calibreID
rm /tmp/worker1/*
done
Med kommandot “calibredb set_metadata” ställer jag in allt annat som taggar. Resultatet ser ut så här:
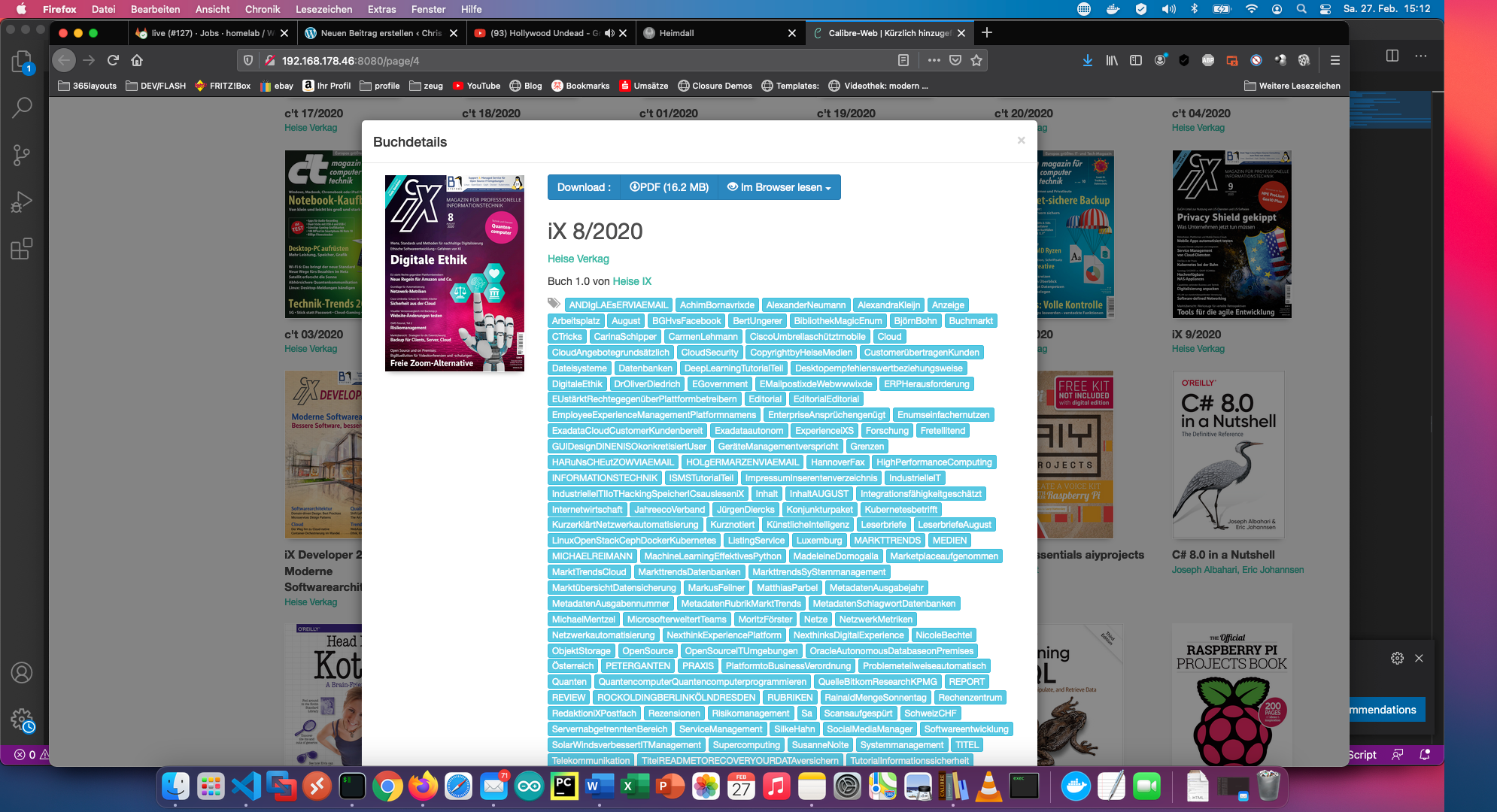
Skriptet finns också på Github: https://github.com/ChristianKnedel/heise-ix-reader-for-calibre .