在PDF中添加正确的元信息往往是很乏味的。我自己将下载的PDF文件从我的Heise IX订阅账户中分类到我的私人Calibre图书馆。
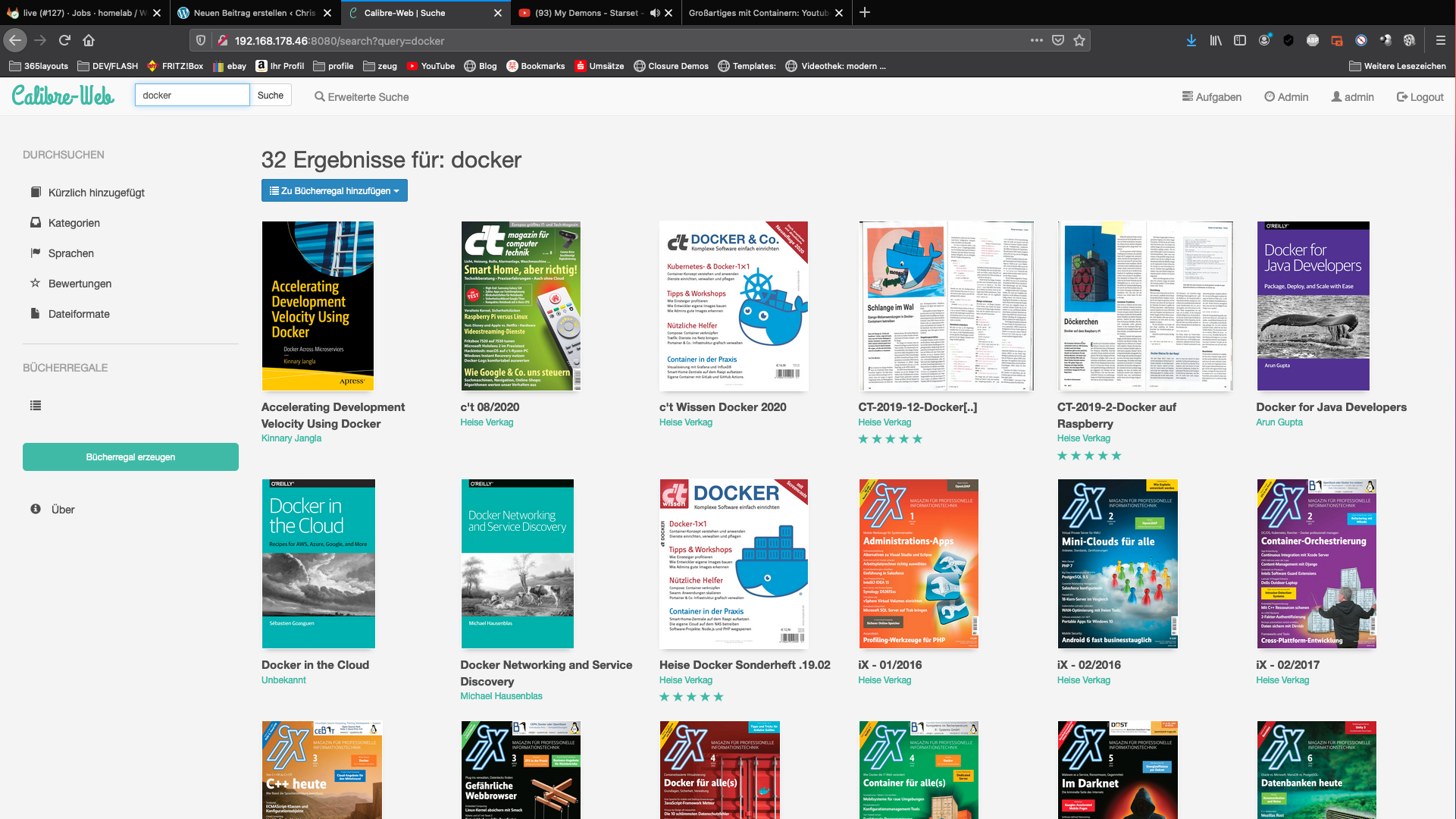
因为这个过程每个月都在重复,所以我想出了以下设置。我只把我的新PDF拖入我的资料库。
我已经创建了一个容器,将我的Calibre库作为一个卷(-v …:/books)获得。在这个容器中,我安装了以下软件包。
$ apt-get update && apt-get install -y xpdf calibre
#!/bin/bash
export LANG=C.UTF-8
mkdir /tmp/worker1/
find /books/ -type f -iname '*.pdf' -newermt 20201201 -print0 |
while IFS= read -r -d '' line; do
calibreID=$(echo "$line" | sed -r 's/.*\(([0-9]+)\).*/\1/g')
echo "bearbeite $clearName"
echo "id $calibreID";
cp "$line" /tmp/worker1/test.pdf
echo "ocr "
pdftotext -f 0 -l 5 /tmp/worker1/test.pdf /tmp/worker1/tmp.txt
echo "text aufbereitung"
cat /tmp/worker1/tmp.txt | grep -i -F -w -v -f /books/blacklist.txt | sed -r s/[^a-zA-ZäöüÄÖÜ]+//g | grep -iE '[A-Za-z]{2,212}' | sed ':begin;$!N;s/\n/,/;tbegin' > /tmp/worker1/final.txt
calibredb set_metadata --with-library /books/ --field cover:"cover.jpg" --field tags:"$(cat /tmp/worker1/final.txt) " --field series:"Heise IX" --field languages:"Deutsch" --field authors:"Heise Verkag" $calibreID
rm /tmp/worker1/*
done
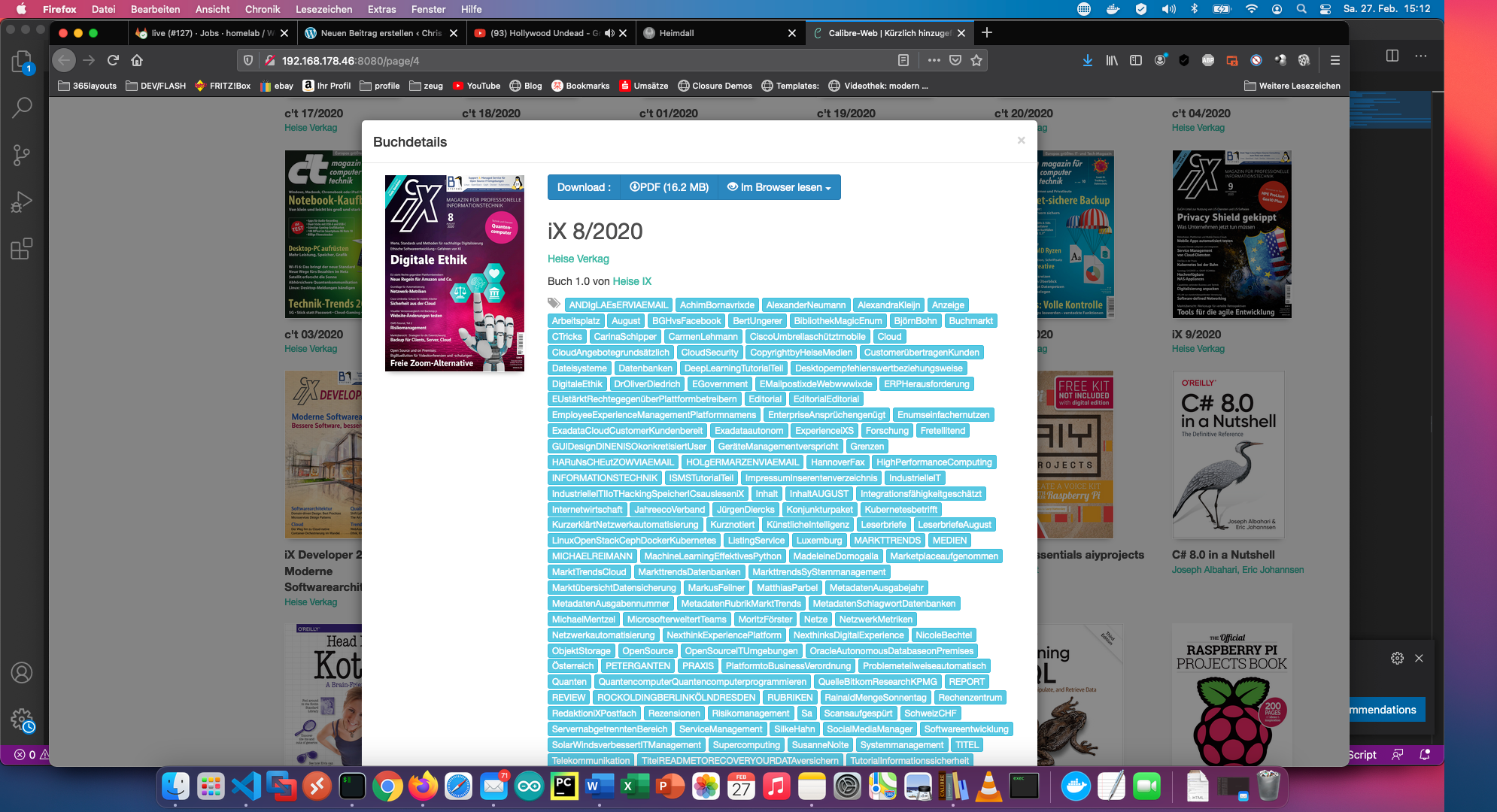
通过 “calibredb set_metadata “命令,我把其他一切都设置为标签。结果看起来是这样的。
该脚本也可以在Github上找到:https://github.com/ChristianKnedel/heise-ix-reader-for-calibre 。